
In a recent research project, we researched possibilities for interactive storytelling, usability, and interaction methods of an Augmented Reality app for patient education. We developed an ARCore app with Unity that helps patients with strabismus to better understand the processes of examinations and eye surgeries. Afterwards, we performed a 2-phase evaluation with a total of 24 test subjects.
We published the results at the IEEE VR conference. The peer-reviewed paper is available through the open access online proceedings or on ResearchGate.
A brief overview of the main findings:
Health Literacy and Education
Low health literacy is a well-known and serious issue. 1 in 5 American adults lack skills to fully understand implications of processes related to their health . Audio and computer-aided instructions can be helpful. Especially spoken instructions lead to a higher rate of understanding . A smartphone app that combines multiple approaches can therefore provide great benefits.
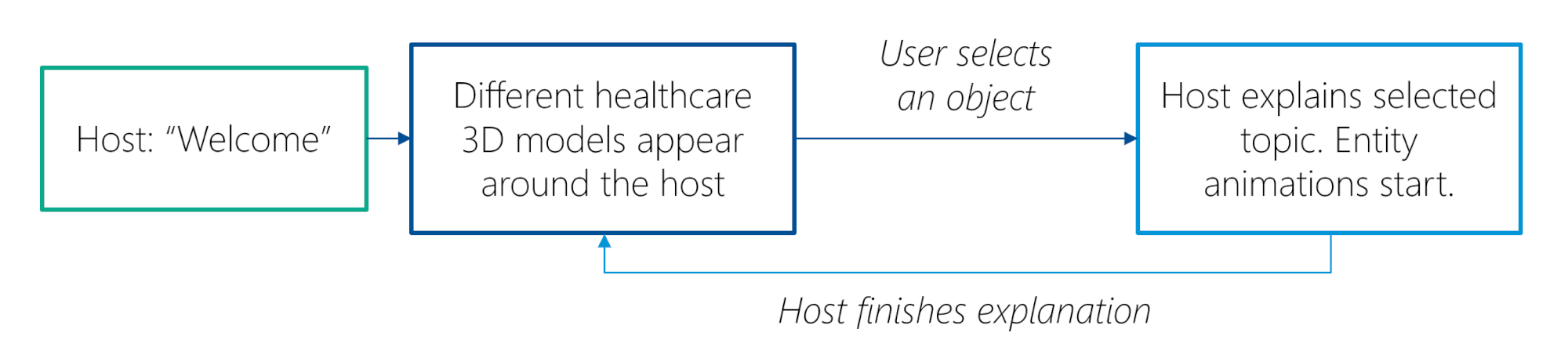
We developed and evaluated a prototype Augmented Reality (AR) mobile application called Enlightening Patients with Augmented Reality (EPAR). The app is designed for patient education about strabismus and the corresponding eye surgery. It is intended to be used in addition to the doctors’ mandatory consultations.





You must be logged in to post a comment.