For a realistic Augmented Reality (AR) scene, a depth map of the environment is crucial: if a real, physical object doesn’t occlude a virtual object, it immediately breaks the immersion.
Of course, some devices already include specialized active hardware to create real-time environmental depth maps – e.g., the Microsoft HoloLens or the current high-end iPhones with a Lidar sensor. However, Google decided to go into a different direction: its aim is to bring depth estimation to the mass market, enabling it even for cheaper smartphones that only have a single RGB camera.
In this article series, we’ll look at how it works by analyzing the related scientific papers published by Google. I’ll also show a Python demo based on commonly used comparable algorithms which are present in OpenCV. In the last step, we’ll create a sample Unity project to see depth maps in action. The full Unity example is available on GitHub.
Quick Overview: ARCore Depth Map API
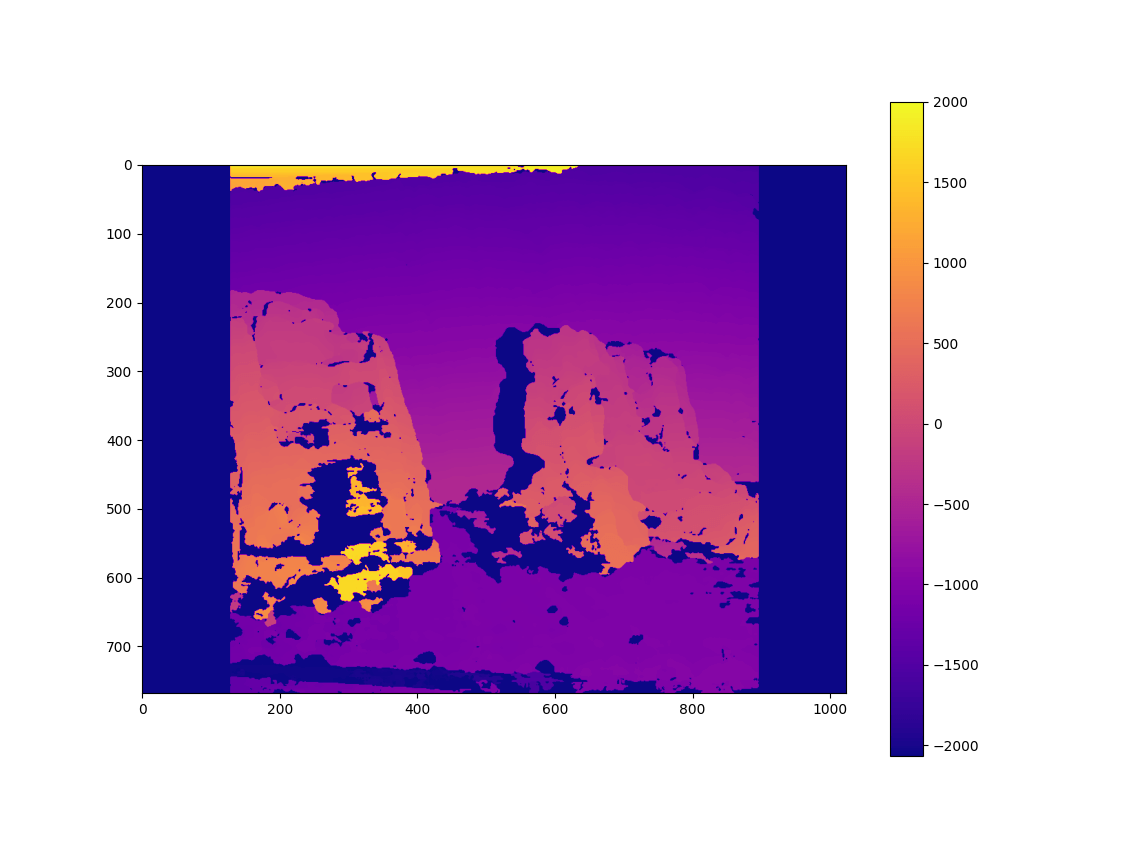
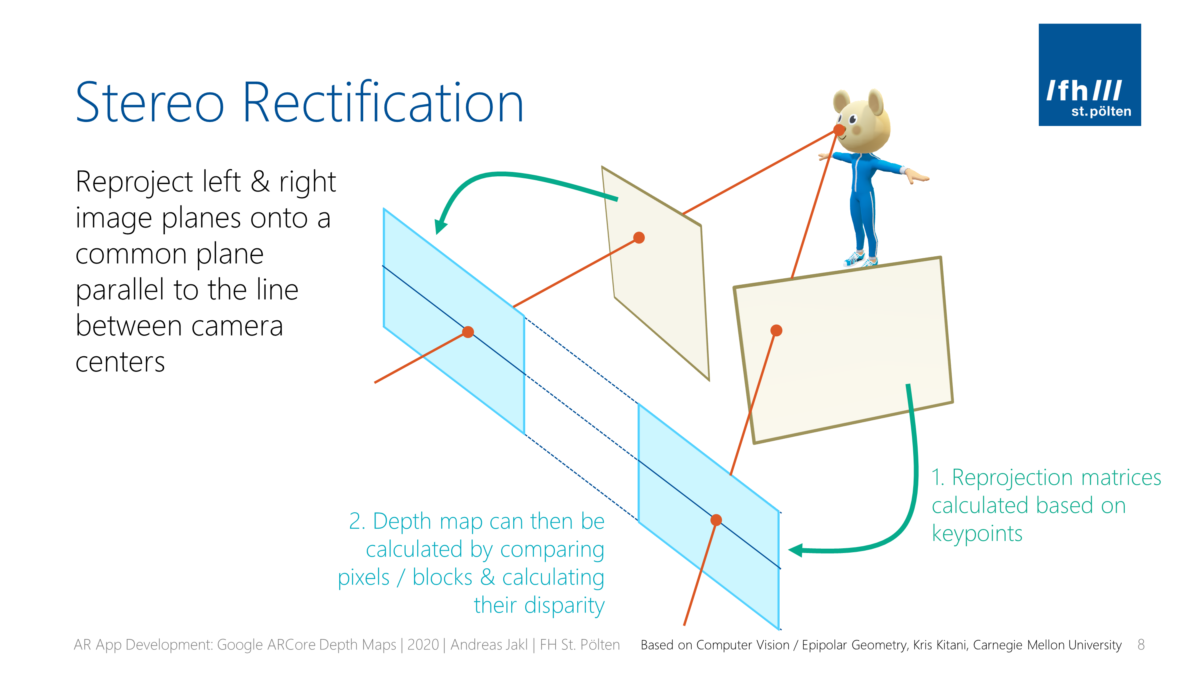
How do Depth Maps with ARCore work? The smartphone saves previous images from the live camera feed and estimates the phone’s motion between these captures. Then, it selects two images that show the same scene from a different position. Based on the parallax effect (objects nearer to you move faster than these farther away – e.g., trees close to a train track move fast versus the mountain in the background moving only very slowly), the algorithm then calculates the distance of this area in the image.
This has the advantage that a single-color camera is enough to estimate the depth. However, this approach needs structured surfaces to detect the movement of unique features in the image. For example, you couldn’t get many insights from two images of a plain white wall, shot from two positions 20 cm apart. Additionally, it’s problematic if the scene isn’t static and objects move around.
As such, given that you have a well-structured and static scene, the algorithm developed by Google works best in a range between 0.5 and 5 meters.






You must be logged in to post a comment.